LLM Wiki vs. RAG Knowledge Base
Is Andrej Karpathy’s Design Pattern Truly Revolutionary?
 Piotr Chlebek · 2026-4-15
Piotr Chlebek · 2026-4-15
Abstract: The article analyzes Andrej Karpathy's innovative "LLM Wiki" design pattern, which serves as an alternative to traditional RAG systems. The author describes the process of actively compiling raw data into a persistent Markdown knowledge base, facilitating the autonomous accumulation and synthesis of information. The text thoroughly contrasts the benefits of this new architecture with its operational challenges while highlighting a wide range of potential applications.
Keywords: LLM Wiki, Andrej Karpathy, RAG (Retrieval-Augmented Generation), AI Knowledge Base, Data Distillation, Knowledge Management, Knowledge Compilation, Markdown Wiki, LLM Cost Optimization, Personal Knowledge Base (PKB), Second Brain, Semantic Drift, RAG Engineering, Obsidian AI, Knowledge Audit (Linting).
LLM Wiki vs. RAG
In early April 2026,  Andrej Karpathy introduced a new design pattern —
LLM Wiki [1].
It is a framework for building personal knowledge bases using language models.
The idea looks promising as it attempts to address significant weaknesses of LLM+RAG systems.
It introduces new mechanisms and supplements the system with a knowledge base whose expansion and maintenance can be fully autonomous (managed by the LLM), while remaining human-auditable.
It solves the problem of knowledge non-accumulation and improves the ability to synthesize information from multiple sources.
Andrej Karpathy introduced a new design pattern —
LLM Wiki [1].
It is a framework for building personal knowledge bases using language models.
The idea looks promising as it attempts to address significant weaknesses of LLM+RAG systems.
It introduces new mechanisms and supplements the system with a knowledge base whose expansion and maintenance can be fully autonomous (managed by the LLM), while remaining human-auditable.
It solves the problem of knowledge non-accumulation and improves the ability to synthesize information from multiple sources.
“The idea here is different. Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki — a structured, interlinked collection of markdown files that sits between you and the raw sources.”
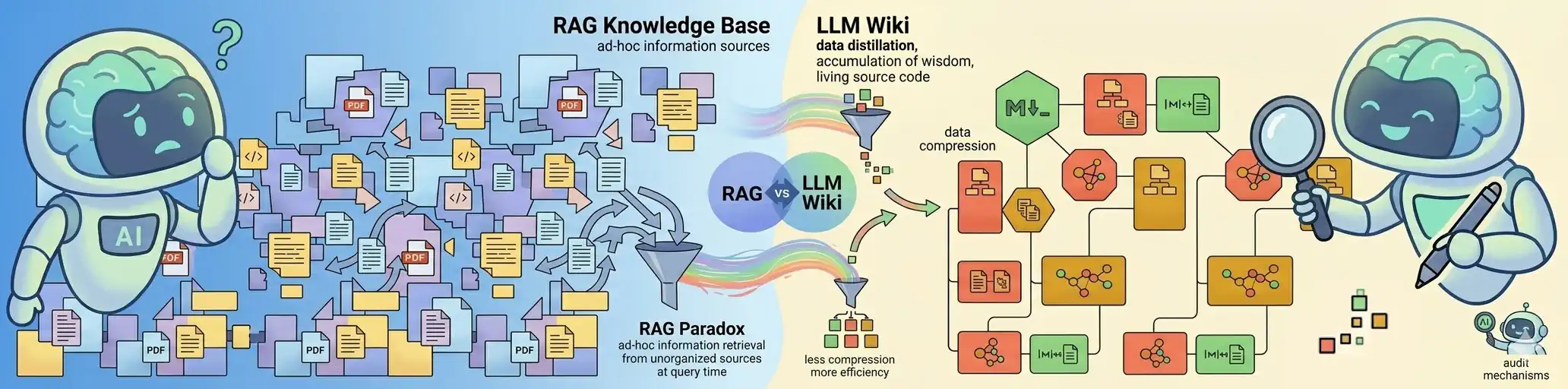
LLM Wiki is a “Wiki-First” type of RAG system. It uses a RAG mechanism to search a knowledge base that is continuously created and updated by the model itself. As a result, the system “learns” and builds an increasingly broader context over time, rather than starting from scratch with every new query.
This concept represents a paradigm shift:
A move from retrieval (RAG) to the compilation of raw documents into a coherent, constantly updated knowledge base.
It treats knowledge not as a static library to be searched, but as “living source code” that AI actively rebuilds and maintains.
Key Differences in a Nutshell
Since LLM Wiki is still a novelty, I focused this comparison primarily on the conceptual level. Of course, not all RAGs are created equal, and LLM Wiki itself will evolve over time. However, certain fundamental differences are already plain to see. Only when we recognize them and understand their real impact and limitations will we be able to build top-tier solutions with full awareness.
Here is an interesting comparison of the differences between LLM Wiki and RAG, based on
article [2]
by Emily Winks.
According to the author:
“The sharpest differences appear at three axes: scale, infrastructure, and governance. LLM wikis win on simplicity and token efficiency below the 50,000-100,000 token threshold. RAG wins on scale, dynamism, and multi-user access. Neither wins on enterprise data governance - that requires a separate layer entirely.”
Summary of the most important points:
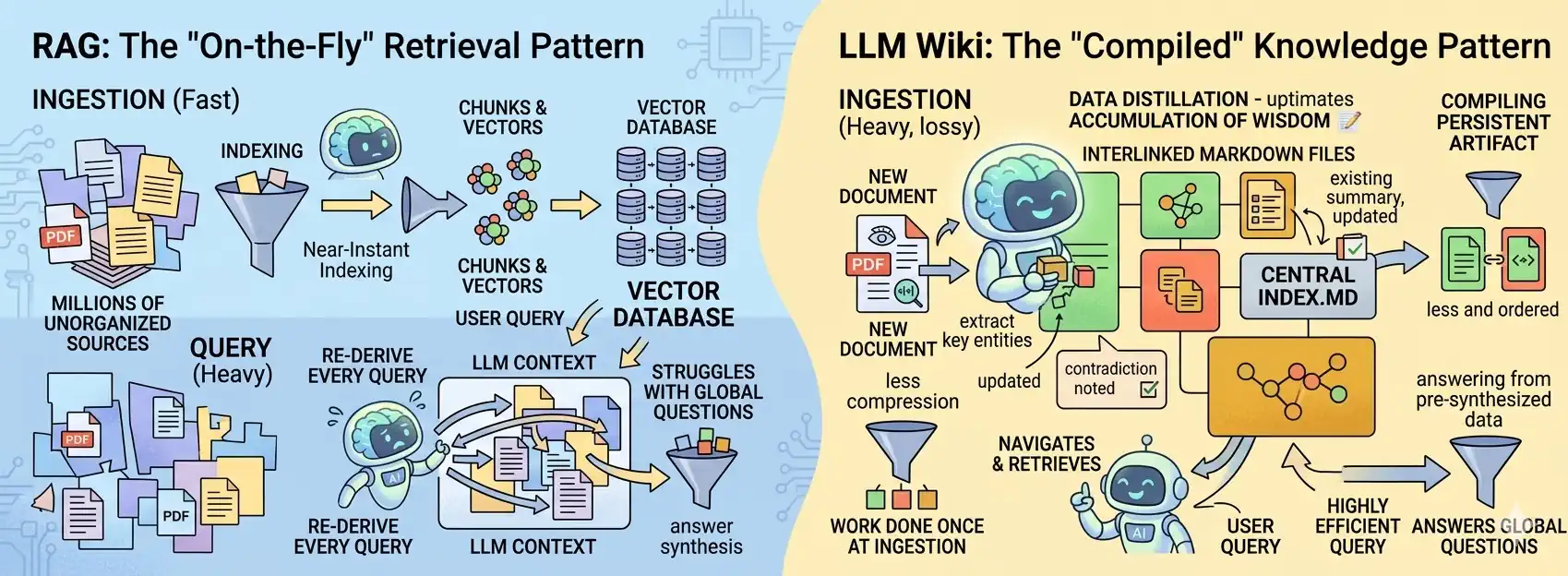
- Architecture: LLM Wiki loads the entire, organized index into the context. RAG works differently – at the moment a question is asked, it dynamically “pulls” specific fragments of knowledge from a vector database.
- Scale: LLM Wiki performs great within the 50–100 thousand token limit. RAG has no “ceiling” – (when building a vector database) it can handle millions of documents.
- Infrastructure: LLM Wiki is a nearly maintenance-free solution – you don’t need additional backend infrastructure. RAG requires a whole machinery: a vector database, embedding mechanisms, and a retrieval layer.
- Data Management: Neither approach solves corporate data security on its own. A separate system is required, such as a professional data catalog with advanced access control.
The RAG Paradox: Why Are We Reinventing the Wheel?
Currently, RAG (Retrieval-Augmented Generation) is the standard. You feed in documents, ask a question, and the AI searches the database. Sounds good? Only on the surface. RAG comes with dozens of challenges – it requires a solid engineering approach and strong architectural foundations. With every query, the system searches the entire collection of documents (or rather, their fragments), selects the most important information, and starts all synthesis work from scratch. Of course, identical queries can be handled by the cache. However, if you ask something very similar tomorrow, the basic RAG will once again pull the same document fragments (often a fairly large stack), rearrange them, and will have to laboriously piece together the meaning from this jumble all over again.
To make matters worse, processing happens on a limited number of text fragments, meaning the vast majority of them will not be analyzed when constructing the answer. While this is somewhat desirable – we don't want to consider content unrelated to the question – it has side effects. Very often, loosely related fragments that are still important in a given context are simply omitted.
LLM Wiki reverses this process. Instead of searching for information only at query-time, we compile knowledge at ingest-time. AI becomes your personal editor, rewriting and connecting facts into a coherent whole in real-time. This way, we don’t have to search all documents from scratch with every query. It’s enough to insert the already compiled knowledge into the context (if it fits the context window) or a selected, organized part of it (when the base is too extensive or LLM limits are too restrictive). In the LLM Wiki approach, the knowledge base is significantly more stable. Even if you change the query, the AI operates on the complete set of information every time, ensuring significantly higher response consistency.
LLM Wiki: A Revolution or Just Andrej Karpathy's "Hype"?
Opinions are divided. Skeptics criticize it as nothing groundbreaking, arguing the solution has no future and does not scale. Optimists praise the elements that function better and paint joyful visions of the future of LLM Wiki. I think it is still too early to decide. Instead, I suggest we look at the pros and cons of this solution.
Looking at this issue systematically, I see great value in separating the knowledge base (or knowledge graph) from the LLM and the RAG mechanism themselves. However, I have doubts whether a Wiki, as a data organization model, will hold up at a large scale and whether we might need a different abstraction here. Indeed, the Wiki format is extremely useful when a human audits the content or when we transfer knowledge into the prompt context.
However, the gathered knowledge could reside in dedicated structures, while a separate tool layer handles its auditing and feeding into the model.
Such tools could simply extract the data and convert it into a readable Markdown format only when needed.
Although the topic is relatively fresh, there have already been attempts to use LLM Wiki in combination with a knowledge graph — see, for example, video [3] by Nodus Labs.
In this post:
- LLM Wiki vs. RAG
- LLM Wiki: A Revolution or Just Andrej Karpathy's "Hype"?
- The Potential and Benefits of LLM Wiki
- Challenges and Limitations of LLM Wiki
- LLM Wiki Use Cases
- Battle Summary: LLM Wiki vs. RAG
Related Posts:
- AI Tinkerers Gdańsk Meetup – April 23rd
- RAG isn't about AI; it's about engineering
- Serving the LLM locally with vLLM
- Hybrid RAG with Semantic Chunking
References:
- [1] GitHub: karpathy/llm-wiki.md - Andrej Karpathy
- [2] Article: LLM Wiki vs RAG Knowledge Base: The Karpathy Approach Explained - Emily Winks
- [3] YouTube: Fix Karpathy’s LLM Wiki with a Knowledge Graph | Claude Code + Obsidian + InfraNodus - Nodus Labs
Images Source: Google DALL-E 3 (04.2026).
The Potential and Benefits of LLM Wiki
The LLM Wiki concept is a promise that our knowledge will cease to be an impenetrable pile of thousands of links. It will become a dynamic description of essential topics—a condensed "capsule" containing key information and the relationships between them. It is a place where, as if through a lens, you can focus on what truly matters and conveniently manage scattered data. Here is why this approach is capturing so many imaginations:
A Breakthrough in Efficiency and Costs
- Extreme Compression (Distillation): The promise of a 95% reduction in data consumption is a financial revolution.
Instead of paying to send fragments of raw documents to the model every single time, you pay only once to distill them into condensed, clean Markdown notes.
The perceived cost increase from including the full wiki in the context can be mitigated effectively through Prompt Caching.
As noted by the author himself [1]:
[On RAG] „LLM is rediscovering knowledge from scratch on every question. There's no accumulation”
[On LLM Wiki] „The knowledge is compiled once and then kept current, not re-derived on every query” - Higher Answer Precision: Focusing on the "essence" eliminates informational noise. The model doesn't get lost in long contexts (the so-called lost-in-the-middle effect), which translates into more accurate conclusions.
- Instant Response Time: A smaller and cleaner input context means the model generates responses significantly faster, bringing us closer to fluid, real-time interaction.
- Simplified Tech Stack: Moving from costly vector databases and complex servers to a simple file system makes the system cheaper, easier to maintain, and more resilient to failure.
A New Quality of Knowledge (AI as a Digital Librarian)
- Cumulative Wisdom: Knowledge in an LLM Wiki "grows" and matures organically. Insights gained months ago automatically connect with new data, meaning the system actually gets smarter with every added file.
- Conflict Detection (Linting): This is the "knowledge compilation" mechanism. During an audit, the AI detects conflicts between new facts and old notes, forcing us to resolve what is true and what is an error in reasoning.
- Automatic Standardization: Whether the source is a chaotic transcript or a technical PDF, LLM Wiki converts everything into a consistent, structured format that is easy to search for both AI and humans.
- Visualizing the "Topology of Thought": Thanks to graphical connection views (Graph View), you can see the map of your knowledge. This allows you to discover non-obvious bridges between distant fields that are invisible in loose files.
Data Sovereignty and Security
- True Ownership (Human-Readable): Your knowledge consists of text files on your drive. Even if AI providers disappear, your database stays with you—it remains readable by humans and any simple editor for decades to come.
- Privacy Through Locality: The ability to run audit and search processes entirely offline (via local models) allows for the secure processing of the most sensitive corporate secrets or intimate thoughts.
- Transparency and a "Paper Trail": Every claim in the Wiki has a direct reference to the source file in the raw/ folder. This drastically reduces hallucinations and allows you to verify where the AI drew a specific conclusion from in seconds.
Psychological Relief and Cognitive Offloading
- An End to Guilt (Anti-FOMO): You can collect hundreds of interesting articles without the stress of not having read them. You have the confidence that the AI will "digest" them and serve you their essence exactly when you ask about a given topic.
- Focus on Creating, Not Cleaning: The AI takes over the tedious role of the archivist—handling tags, formatting, and internal linking. You remain the architect, focusing solely on asking questions and connecting facts.
- Fulfilling the "Second Brain" Promise: This is the ultimate realization of the Second Brain vision. Technology finally removes the biggest barrier that discouraged users: the need for manual, painstaking maintenance of order in one's notes.
According to enthusiasts, LLM Wiki marks the right direction for the development of personal AI systems. Instead of building massive and heavy "data warehouses," we focus on precise "knowledge distilleries." It is a fundamental paradigm shift: moving from raw quantitative processing to building deep, structural understanding.
Challenges and Limitations of LLM Wiki
While Andrej Karpathy’s vision sounds incredibly tempting, its implementation introduces a range of unique challenges and technical limitations. Since the LLM is no longer just a reader but becomes an active author and editor of the knowledge base, the requirements for precision and maintaining system consistency increase significantly. It is worth analyzing the primary difficulties and barriers inherent in this pattern:
Architecture and Scaling Barriers
- The Index Bottleneck: This is a critical limit—the growth of the index.md file can exceed the model's context window. This forces the creation of sub-indices, which unnecessarily complicates the system architecture.
As noted by the author himself [1]:
"This works surprisingly well at moderate scale (~100 sources, ~hundreds of pages)…"
- Lossy Compression (Loss of Detail): During the distillation of content into the wiki format, the AI inevitably loses subtle details. If a user needs to reach a specific source nuance, the system will force a return to the raw files anyway, which undermines the point of full automation.
- Lack of Transactionality (Race Conditions): Markdown is not a SQL database. If an agent and a human (or two agents) begin editing the same file simultaneously, we risk "conflict hell," data loss, or synchronization errors. This is a major barrier to teamwork.
- Lack of Native RBAC (Permissions): In a system based on text files, selective access is difficult to achieve. The agent usually needs to see everything to build relationships, which precludes keeping sensitive and general data in a single database.
Economics and System Performance
- Dependency on "Heavyweight" Models: LLM Wiki requires top-tier reasoning (e.g., the most powerful available LLM models). Attempting to run audits or compilation on smaller, local models usually results in structural failure and linking errors.
- High Operational Cost: Processing a single new piece of information requires the model to perform multiple read and write operations across different files. This is significantly more expensive and taxing on the API than simply generating an embedding in classic RAG.
According to the author [1]:
„A single source might touch 10-15 wiki pages.”
- The "Compilation Tax": The initial compilation of a large base (e.g., 1,000 documents) can generate a massive bill and take hours. It is an investment that pays off over time, but it requires a significant budget and patience at the start.
Risk of Degradation and Hallucinations
- Semantic Drift (The "Telephone Game"): When an AI summarizes a summary, simplifications and accumulated minor errors occur over time. After several update cycles, your knowledge base could become a superficial caricature of the original.
- Blindness to Contradictions: If conflicting information does not fall within the current context window during an audit, the AI may miss it. This leads to the creation of "muddy" and contradictory articles, which the model then treats as a new absolute truth.
- Structural Hallucinations: AI loves to "force" connections between unrelated concepts or create incorrect internal links. Without hard validation (linting), the base will quickly fill up with logical "monstrosities" that are difficult to catch.
The Human-in-the-Loop Maintenance Barrier
- High Supervision Cost: The workload shifts from writing to the tedious task of checking whether the bot has "messed up" the file structure. Without active human involvement, the system can quickly turn into a digital attic full of dead links.
- "Prompt Fatigue": Creating instructions that rigorously enforce YAML formatting and data schemas requires extensive testing and constant correction following model errors.
- Dependency on Third-Party Tools: By building a system around specific tools (e.g., Obsidian + specific plugins), you become their hostage. Any change in how Markdown is rendered may require a painful overhaul of the entire architecture.
According to optimists, LLM Wiki is currently the most ambitious attempt to organize digital chaos. While this technology requires discipline and high initial costs, it offers something that no classic RAG can: a living, maturing knowledge structure instead of a dead archive of files. Ultimately, the success of this approach depends on whether we accept a new role—no longer just data collectors, but active editors of our own wisdom.
LLM Wiki Use Cases
The author identifies five primary use cases for the LLM Wiki [1]:
- Personal Knowledge Management (PKM): Centralizing diverse data and reflections to track long-term growth and build a structured digital portrait of one's life.
- Research: Synthesizing the long-term accumulation of complex information to refine an evolving thesis and flag inconsistencies across sources.
- Literary & Media Companion ("Reading a book): Creating a dynamic, interlinked wiki that automatically maps characters, themes, and narrative connections as the user consumes content.
- Business & Teams: Maintaining a self-updating internal knowledge base that transforms fragmented communication (Slack, meetings) into a cohesive, evergreen resource.
- Competitive analysis, due diligence, trip planning, course notes, hobby deep-dives: Anything where you're accumulating knowledge over time and want it organized rather than scattered.
I have a feeling that many more use cases for the LLM Wiki will emerge. I can imagine plenty of scenarios where active knowledge synthesis is the perfect fit—especially when the volume of documentation is relatively small. For example:
- Chatbot or Voicebot POCs: Many companies deploying a chatbot or voicebot for the first time don't have a massive knowledge base yet. Transforming existing info into a wiki is a "godsend" for those taking their first steps. It converts loose, unstructured documents into a manageable and actionable format. Reviewing and versioning this knowledge base is critical when rolling out subsequent POC iterations.
- Voice Notes: It’s hard to expect a collection of voice notes to have any deep structure. Sure, a recording has a date, and a meticulous user might assign topics or tags. However, as the notes pile up, it becomes difficult to find relationships between data points or specific details that fall outside simple labels. Using an LLM Wiki offers a way to not only search these notes more easily but also analyze them, allowing contradictions and inconsistencies to be efficiently flagged and resolved.
- Narrative & World-building for Creators: Writers and Game Masters often struggle with "continuity drift." If you're writing a novel or running a complex D&D campaign, an LLM can ensure that a reference to a character's past in a later chapter automatically triggers a contradiction flag if it differs from the initial description. The system effectively acts as a Continuity Editor.
- Technical Debt & Documentation Mapping: Source code often evolves faster than its documentation. By feeding an LLM Wiki with Git commits and Pull Request descriptions, you can maintain a high-level "System Architecture" wiki. This bridges the gap between raw code (Sources) and developer mental models (Wiki), identifying where new features might collide with legacy logic.
- Legal or Medical Case Management: These fields involve massive volumes of "Raw Sources" (medical records, court filings) where data synthesis is mission-critical. An LLM Wiki could maintain a "Master Timeline" or "Evidence Summary" that stays updated as new documents are ingested. A linting function would be invaluable here for detecting conflicting testimonies or gaps in a patient's medical history.
- Career & Personal Brand Ledger: It’s easy to lose track of achievements over the years. By processing performance reviews, project retrospectives, and emails, an LLM can build a structured wiki of your skills and success stories using the S.T.A.R. method (Situation, Task, Action, Result). When it’s time to update your CV or prep for an interview, the synthesis is already done.
Battle Summary: LLM Wiki vs. RAG
In 2026, RAG has become exceptionally useful, widespread, and optimized. It is available in many different "flavors," and its ecosystem continues to grow. RAG is used in production across thousands of projects; many of its features are already well-known to us. We also understand its limitations and the problems for which we have developed effective mitigation strategies.
LLM Wiki (as opposed to classic RAG) is a new concept. This pattern uses the RAG mechanism "under the hood," but in a slightly different way. There are high hopes for this approach, and undoubtedly, as it evolves, LLM Wiki could become a compelling alternative. LLM Wiki is the right tool for high-precision, mid-sized contexts where synthesis matters more than database size. However, it can be much less efficient in use cases where RAG is the superior choice.
I think it is still too early to migrate RAG-based production systems to LLM Wikis. However, it is worth running experiments to see how well this new pattern fits a specific problem or domain. This is especially true when dealing with a very small number of documents in the knowledge base. It’s worth keeping an eye on things, as I feel we are in for some interesting developments with this idea, and new solutions similar to LLM Wiki may prove to be even more revolutionary and useful.